
Premiers codes sources pour l’anonymisation des interactions en ligne
Retrouvez ici les premiers codes sources, testés sur le corpus Simuligne, pour transformer systématiquement les graphies représentant des données personnelles ou identifiant les acteurs. Les principes sont exposés dans l’article et les codes sources documentés sont téléchargeables à travers cet article.
Mise à disposition de nos premiers codes sources pour l’anonymisation des interactions en ligne
En bref :![]() Quoi ? Source Java pour anonymisation : Programme java (incluant les sources) permettant de réaliser le processus d’anonymisation d’un document (ensemble d’interactions chat/mail/forum) selon une structuration XML spécifique. NB : Ce programme n’est plus maintenu.
Quoi ? Source Java pour anonymisation : Programme java (incluant les sources) permettant de réaliser le processus d’anonymisation d’un document (ensemble d’interactions chat/mail/forum) selon une structuration XML spécifique. NB : Ce programme n’est plus maintenu.![]() Qui ? (Auteur : E. Gasche) : Ce programme a été développé par le LIUM (Laboratoire d’Informatique de l’Université du Maine) en partenariat avec le LIFC (Laboratoire d’Informatique de l’Université de Franche-Comté) dans le cadre d’une ACI (projet national) « ODIL » (Outils et Didactique pour les Interactions en Ligne). Les principaux contributeurs scientifiques sont C. Reffay (LIFC) et P. Teutsch (LIUM), le développeur (auteur du programme source déposé) étant Emmanuel Gasche (LIUM).
Qui ? (Auteur : E. Gasche) : Ce programme a été développé par le LIUM (Laboratoire d’Informatique de l’Université du Maine) en partenariat avec le LIFC (Laboratoire d’Informatique de l’Université de Franche-Comté) dans le cadre d’une ACI (projet national) « ODIL » (Outils et Didactique pour les Interactions en Ligne). Les principaux contributeurs scientifiques sont C. Reffay (LIFC) et P. Teutsch (LIUM), le développeur (auteur du programme source déposé) étant Emmanuel Gasche (LIUM).![]() Destiné à qui ? Des développeurs…
Destiné à qui ? Des développeurs…![]() Pour quoi faire ? …Réutiliser tout ou partie des codes sources pour développer de nouveaux outils d’anonymisation.
Pour quoi faire ? …Réutiliser tout ou partie des codes sources pour développer de nouveaux outils d’anonymisation.
Que fait ce programme (Anonymiseur) ?
Le texte ci-après est extrait du rapport de recherche (12p) de 2007 :
Reffay, C. & Teutsch, P. Anonymisation de corpus. Rapport de recherche (12 p.) disponible en ligne. http://edutice.archives-ouvertes.fr/edutice-00158877/fr/
Les questions qui se posent à l’anonymisateur sont les suivantes : quels données existent dans le corpus d’origine, quelles données ne peuvent perdurer, quelles données sont attendues par l’analyste dans le corpus produit ? Deux approches complémentaires permettent de répondre. La première s’appuie sur les modèles de corpus disponibles, la seconde sur la réalité des interventions constituant le corpus.
Conceptuellement, les modèles de situations d’apprentissage existants distinguent les données liées à l’identité de la personne (nom, prénom, surnom, photo), les données liées à ses caractéristiques sociales (sexe, âge, localisation géographique, langue maternelle) et les données liées à son profil d’apprentissage (niveau et compétences en langue cible, parcours et trajet de formation, situation courante). Parmi ces données, seul le premier lot est sujet à modification, les autres peuvent se révéler indispensables pour certaines analyses.
La suite présente le processus d’anonymisation utilisé par ViCoDiLi pour le corpus Simuligne. Ce processus s’appuie sur la définition des données d’identité à protéger, sur une table de correspondance attribuant un masque de remplacement à chaque donnée d’identité, et sur un traitement en plusieurs phases du corpus.
Le processus d’anonymisation proposé s’articule en deux phases s’appuyant chacune sur une base d’informations. En aval, le corpus anonymisé est produit à partir d’un ensemble de correspondances entre les formes d’origine des identités et les formes de remplacement de ces identités. En amont, le propriétaire du corpus s’appuie sur l’ensemble des informations individuelles dont il dispose pour préparer la table de correspondance en tenant compte de ce qu’il connaît des acteurs, du contenu des échanges, et des besoins de l’analyse.
Ce processus permet au propriétaire de conserver le profil complet des acteurs afin de toujours pouvoir recréer le lien vers certaines caractéristiques, de définir la logique des équivalences entre les éléments réels d’identité et leurs pseudonymes, et de définir au besoin des équivalences complémentaires à partir d’expressions repérées dans les échanges. Le principe de conversion entraîne le masquage des noms, prénoms, surnoms et autres diminutifs signalés par l’opérateur en pseudonymes. Le terme « pseudonyme » désigne la forme modifiée de l’identité initiale.
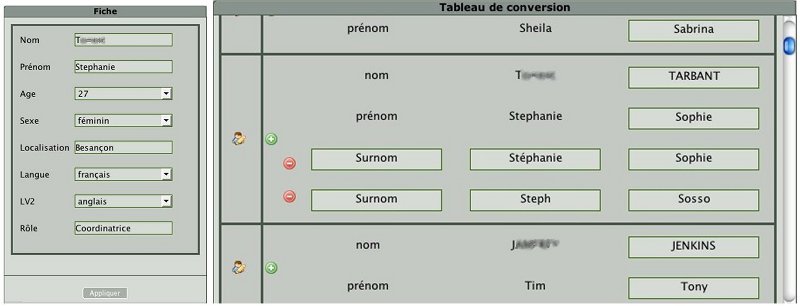
L’utilisateur anonymisateur dispose d’une interface de description des correspondances entre identité d’origine et identité modifiée (Figure 1). Le système présente dans un premier temps la liste des intervenants connus du corpus (liste issue de la plateforme de formation en ligne via un fichier XML). L’utilisateur peut compléter cette liste avec les surnoms, diminutifs et formes altérées présentes dans le corpus, permettant ainsi de désigner chacune de ces personnes à partir de la déclinaison de leur identité, ce qui impose de bien connaître le corpus ! Le système signale à l’opérateur les doublons repérés dans la table de correspondance. Ces doublons peuvent correspondre à de réels homonymes d’origine, il est alors recommandé de leur attribuer le même masque afin de maintenir l’ambiguïté d’origine. Les doublons peuvent aussi être fortuits (deux masques identiques pour des données différentes dans le corpus d’origine), le système présente alors les différentes formes utilisées pour que l’opérateur vérifie ses déclarations.
La table de correspondance entre identités d’origine et pseudonymes est accompagnée d’un ensemble de fiches (Figure 1). Chaque fiche contient les caractéristiques réelles de l’acteur de la formation : identité complète, âge, localisation, … Ces informations, uniquement connues du propriétaire, ont pour but de l’aider à choisir un pseudonyme en tenant compte, si besoin, de certaines caractéristiques du profil de l’acteur (rôle, sexe, langue, culture, etc.).
Le processus d’anonymisation en lui-même consiste à appliquer les modifications dans le corpus d’origine (fichier XML) en deux phases : modification des identifiants des acteurs dans les en-têtes des interventions puis modification dans le corps des interventions. Ce processus transforme le contenu sans altérer la structure XML, ce qui permet à ViCoDiLi de visualiser également le nouveau corpus.
Voir en ligne : Téléchargement de la ressource
Licences d’utilisation des corpus MULCE
Pour permettre à d’autres chercheurs ou enseignants de pouvoir réutiliser tout ou partie de votre corpus,ce corpus peut être utilisé à des fins de recherche ou d’enseignement suivant la licence Creative Commons de type by-nc-sa. Ces utilisateurs peuvent donc dans le cadre de leurs activités professionnellesen faire des produits dérivés à des fins d’enseignement et de recherche, en reconnaissant la paternité du travail aux créateurs (responsable et collecteurs) de ce corpus. S’ils réalisent des produits dérivés, ceux-ci devront également être échangés librement sous cette même licence. Les utilisations commerciales sont interdites (sauf accord explicite du responsable de ce corpus).
Les droits d’auteur
Ceux-ci s’appliquent à toutes les catégories de personnes impliquées dans Mulce, mais le développement qui suit prend pour exemple les apprenants et tuteurs, pour lesquels ce statut est moins immédiatement palpable.
En droit français, est ‘auteur’ toute personne qui crée une oeuvre de l’esprit. Le postulat est fait ici que les données Mulce sont potentiellement des œuvres de l’esprit (car dans le domaine éducatif où nous nous trouvons il est conceptuellement et matériellement difficile de distinguer les données protégeables des données non protégeables au titre du Code de la Propriété intellectuelle, littéraire et artistique). Par conséquent l’apprenant ou le tuteur est considéré comme possédant des droits d’auteur.
En terme de droits d’auteur, l’article L.111-1 du code de la propriété intellectuelle distingue le droit patrimonial (ou droit d’exploiter sa propriété) et le droit moral reconnaissant la paternité d’une oeuvre à son auteur sans limite de durée et permettant à l’auteur de jouir du droit au respect de son nom, de sa qualité et de son oeuvre (art. L. 121-1). Ce droit est imprescriptible.
Lorsqu’un apprenant ou un tuteur signe un contrat donnant l’autorisation à des chercheurs d’utiliser ses paroles (sous forme de traces écrites ou orales) ou une production qu’il a réalisée (page ou site Internet, ou objet numérique), il effectue un seul et même acte qui est susceptible de deux interprétations différentes :
![]() 1. pragmatiquement, cet acte est un acte d’abandon du contrôle de ces données (cession du droit patrimonial)
1. pragmatiquement, cet acte est un acte d’abandon du contrôle de ces données (cession du droit patrimonial)![]() 2. pour autant, cet acte n’efface pas le lien de paternité entre le signataire et ce qu’il a dit, écrit ou numériquement créé (imprescriptibilité du droit moral)
2. pour autant, cet acte n’efface pas le lien de paternité entre le signataire et ce qu’il a dit, écrit ou numériquement créé (imprescriptibilité du droit moral)
C’est dans un esprit de reconnaissance de ce droit moral pérenne que le Code de Pratique de JISC, soucieux de recherche responsable sur des sujets humains potentiellement vulnérables (apprenants) introduit dans les formulaires de demande de Consentement éclairé une clause offrant à tout signataire la possibilité de retirer son consentement ultérieurement, et donc ses données.
La demande de retrait ultérieure peut être motivée par l’intention d’exercer son doit d’auteur, par exemple d’exploiter ses données ailleurs, ou de protéger sa vie privée.
Dans Mulce, la double précaution de :
![]() sollicitation d’une permission d’utilisation)
sollicitation d’une permission d’utilisation)![]() anonymisation des données
anonymisation des données
permet de faire face à ces deux cas de figure. En signant le contrat de cession des droits, les apprenants et tuteurs se déssaisissent de leurs droits d’exploitation et conservent leur lien de paternité moral, mais dans la pratique la probabilité d’un retrait ultérieur devient minime. L’anonymisation, quand à elle, rend caduque la procédure de cession de droits, puisque le lien de paternité entre l’apprenant ou le tuteur et les données n’est plus traceable. Pour ces raisons, Mulce privilégie l’anonymisation à 100% partout où elle est possible.
Protocole de protection de la vie privée
Cadre juridique et contexte régulatoire pour un protocole éthique Mulce
Contexte juridique
Nous sommes souvent dans des situations nouvelles où il faut repenser les anciennes façons de poser les problèmes et adopter une perspective pragmatique qui nous permette d’avancer. Le contexte juridique français est intéressant comme base de réflexion (voir loi du 6 janvier 1978 relative à l’informatique, aux fichiers et aux libertés) mais il est en évolution, et n’est pas à l’heure actuelle suffisamment outillé pour nous aider à faire face aux problèmes qui se posent à nous comme chercheurs en SHS au stade présent de développement de l’Internet. D’autres cadres juridiques européens sont plus précis dans ce domaine (exemple la législation britannique du Data Protection Act, 1998 et du Freedom of Information Act, 2000) et ont inspiré parmi les communautés de chercheurs anglophones des travaux qui nous ouvrent de meilleures perspectives, comme expliqué dans la section suivante.
Contexte régulatoire
Le contexte régulatoire emprunte à un travail (Oates, 2006) qui porte principalement sur les dispositions en vigueur dans le monde universitaire britannique – lesquelles suivent les évolutions en cours dans la recherche nord-américaine. Pour les chercheurs travaillant avec des sujets humains, l’obligation d’adhérer aux principes du respect de la personne a toujours été et reste une question de code professionnel et de bonne pratique. Cependant aujourd’hui des obligations plus concrètes sont venues considérablement renforcer ce contexte. Par exemple dans les domaines disciplinaires alliés à la psychologie, y compris dans certaines branches des sciences de l’éducation, la conduite de la recherche, la soutenance d’une thèse, non plus que la publication de travaux, ne sont possibles sans preuves de la conformité du travail avec le code d’éthique de la British Psychological Society (voir Encadré 2).
| Encadré 2 : Professional organisations |
|---|
| Many British professional organisations have in recent years developed ethical principles and guidelines within which their members are expected to practice and conduct research. Prominent among these are the British Psychological Society, the British Educational Research Association, all of which maintain websites carrying current versions of these codes of practice. […] It is common practice for members of such bodies to state in applications for ethical approval for research that they will conduct their study in compliance with the body’s ethics code. [Oates, 204] |
De façon encore plus précise, on peut dire que les organismes de financement de la recherche au Royaume-Uni et aux États-Unis fonctionnent comme les gardiens des normes éthiques, en exigeant des garanties de plus en plus explicites sur ce plan (voir Encadré 3).
| Encadré 3 : |
|---|
| (a) Funding bodies Research funding bodies are increasingly adopting equivalent sets of ethical guidelines which researchers are expected to comply with in any research funded in part of whole by these agencies. […] The Economic and Social Research Council (ESRC) has published a Research Ethics Framework (Economic and Social Research Council, 2005), with which all researchers in receipt of ESRC support will in future be required to comply. Many funding bodies now require that applications for research funding should have already received formal ethical approval from the host institution, normally a university or other higher education establishment (HEI). [Oates, 204-205] (b) Cross-national funding of research |
Dans cette évolution vers une documentation éthique de plus en plus standardisée, l’exemple du "consentement éclairé" est parlant : il n’est pas ‘exigé’ mais simplement ‘recommandé’ que ce consentement soit formulé comme dans l’Encadré 4 ci-dessous. Mais la logique de compétitivité des soumissions de dossiers fait que les soumettants cherchent à s’assurer les meilleures chances de sélection en fournissant la version détaillée y compris la Clause 14, dont l’application pose un vrai défi aux chercheurs. La frontière entre ce qui est souhaitable et ce qui est obligatoire se déplace insensiblement vers l’obligatoire.
| Encadré 4 : Consentement éclairé Informed consent |
|---|
| Typically, informed consent is gained and documented by using a combination of an information sheet and a consent form. […] COREC (Central Office for Research Ethics Committee) provides a checklist of points that a good information sheet will follow […] |
De plus, il faut noter qu’au regard du droit actuel, le consentement éclairé n’est pas seulement nécessaire pour échanger des données entre chercheurs, mais il conditionne la simple possibilité de pouvoir conserver des données de recherche dans son laboratoire, même sans les utiliser, ni les échanger.
Historique de Mulce : problèmes d’application du cadre juridique
Les données humaines de Mulce sont réparties dans 3 corpus, issus respectivement des projets ‘Simuligne’, ‘Copéas’ et ‘Tridem’, prédatant l’utilisation qu’il est maintenant prévu d’en faire au sein de Mulce. Les individus ont fourni un consentement éclairé autorisant le recueil, le traitement et la dissémination de leurs données selon les finalités qui leur ont été présentées à l’époque par chaque équipe de recherche concernée. Dès lors que Mulce prévoit un transfert des données à d’autres équipes, transfert qui n’a pas été évoqué lors du recueil du consentement d’origine, celui-ci ne peut plus être considéré comme informé. Une difficulté particulière ressort de la possibilité que ces données soient ré-utilisées dans des contextes de recherche non réglementés par la législation européenne.
Approche pratique adoptée par JISC
Le Joint Information Systems Committee (JISC http://www.jisc.ac.uk) est un organisme créé en 1993 pour soutenir l’enseignement supérieur et la recherche britanniques dans tous les domaines touchant aux technologies d’information et de communication. On lui doit un commentaire juridique (Encadré 5), qui présente une approche pratique aux problèmes historiques soulevés plus haut, et permet de fournir une base au protocole Mulce, exposé dans la section 3.2.
| Encadré 5 Extract from JISC Data protection Code of Practice for the Higher Education and Further Education Sectors, Version 2.0 |
|---|
| […T]he 1998 Act provides certain exemptions for “research purposes” including statistical or historical purposes. Section 33 of the 1998 Act exempts personal data used for research purposes from certain Data Protection rules. If the purpose of the research processing is not measures or decisions targeted at particular individuals and it does not cause substantial distress or damage to a data subject, it is exempt from : |
Protocole de protection des droits des participants Mulce
La protection des droits des participants des corpus Mulce (‘Simuligne’, ‘Copéas’ et ‘Tridem’) est assurée de deux façons distinctes, selon qu’un corpus est ‘anonymisé’ ou classé comme ‘sensible’.
L’anonymisation « totale », pour désirable qu’elle soit, ne pourra pas être garantie. Cependant nous y tendrons, par la plus grande application possible de procédures d’anonymisation. Le corpus (ou partie de corpus) sera alors dit « anonymisé » (sauf preuve du contraire et nous corrigerons alors). L’autre cas est l’anonymisation « impossible » ou « très partielle » : dans ce cas les données seront classées sensibles. Le collecteur devra tenter de spécifier / repérer les données qui ne sont pas anonymisées afin de limiter la taille de la partie du corpus classée comme sensible.
Perte d’information et remplacement
Pour les textes écrits ou oraux, l’anonymisation touche en général les patronymes, prénoms et surnoms. Pour les documents audio et visuels, le problème est plus global, touchant le timbre même de la voix, et l’ensemble du visuel (d’une photographie d’identité par exemple). Le remplacement peut se faire de diverses façons, et d’autres projets en SHS les préconisent. Mais ce remplacement peut introduire soit une perte soit un biais.
Dans les cas où l’anonymisation est dommageable pour la recherche, il convient de recourir à l’une de ces deux solutions : le préciser dans l’accord de consentement éclairé des participants, ou à défaut, exclure du dépôt ces données précises, selon des procédures précisées ci-après.
On évitera dans tous les cas de laisser les patronymes.
Parties non anonymisées
Le collecteur, lors du dépôt indique les parties du corpus qui ne sont pas anonymisées. Il indiquera donc pour ces données ce qui permet d’identifier les individus. Il indiquera également le type de permission donné par les participants originels.
Ces précisions seront fournies de façon à ce que les chercheurs susceptibles de ré-utiliser ces corpus soient clairement informés du statut juridique et régulatoire de ces données.
De plus, l’éditeur de corpus fera en sorte :![]() que tous les chercheurs impliqués dans le projet soient informés des conditions d’exemption et de la teneur de leurs obligations comme indiqué dans le Code of Practice du JISC
que tous les chercheurs impliqués dans le projet soient informés des conditions d’exemption et de la teneur de leurs obligations comme indiqué dans le Code of Practice du JISC ![]() qu’avant chaque traitement de données personnelles, une réflexion soit menée sur la conformité du traitement prévu avec les recommandations du Code of Practice du JISC.
qu’avant chaque traitement de données personnelles, une réflexion soit menée sur la conformité du traitement prévu avec les recommandations du Code of Practice du JISC.![]() qu’il soit procédé à un examen annuel des procédures de traitement et de protection des données personnelles en vigueur au sein du projet Mulce
qu’il soit procédé à un examen annuel des procédures de traitement et de protection des données personnelles en vigueur au sein du projet Mulce![]() qu’un mécanisme soit mis en place, permettant de garantir aux individus dont les données personnelles sont - ou vont être – traitées et/ou disséminées le moyen d’exercer leur droit d’opposition
qu’un mécanisme soit mis en place, permettant de garantir aux individus dont les données personnelles sont - ou vont être – traitées et/ou disséminées le moyen d’exercer leur droit d’opposition
Implémentation et gestion de ces dispositions
Outre le paramètre "moderation", dont la valeur régule la mise en ligne des données associées, le système Mulce dispose d’un second paramètre "access". Il fait partie de la structure Mulce-struct. Il prendra les valeurs :![]() "anonymous". Cela indique que les données attachées sont accessibles à tout internaute, sans identification.
"anonymous". Cela indique que les données attachées sont accessibles à tout internaute, sans identification. ![]() "contractual". Ces données sont accessibles aux contractuels.
"contractual". Ces données sont accessibles aux contractuels.![]() "sensitive". Ces données sont accessibles aux contractuels. Mais elles n’ont pas été anonymisées et sont donc susceptibles de voir leurs accès fermés en cas de réclamation d’un ayant-droit.
"sensitive". Ces données sont accessibles aux contractuels. Mais elles n’ont pas été anonymisées et sont donc susceptibles de voir leurs accès fermés en cas de réclamation d’un ayant-droit.
Mulce est un projet "open access". L’accès libre est donc garanti aux chercheurs / enseignants ayant le statut "contractual".
Les valeurs du paramètre sont gérées ainsi ![]() Lors du dépôt, le collecteur déclare que tel ensemble de constituants du corpus est anonymisé ou non. Dans le premier cas, le paramètre access prend la valeur contractual, sinon sensitive.
Lors du dépôt, le collecteur déclare que tel ensemble de constituants du corpus est anonymisé ou non. Dans le premier cas, le paramètre access prend la valeur contractual, sinon sensitive.![]() La valeur anonymous est gérée uniquement par l’équipe Mulce qui, sur ses deux corpus d’apprentissage, Copéas et Simuligne, décidera de ce qui peut-être mis en accès non identifié.
La valeur anonymous est gérée uniquement par l’équipe Mulce qui, sur ses deux corpus d’apprentissage, Copéas et Simuligne, décidera de ce qui peut-être mis en accès non identifié.![]() Lorsqu’un internaute identifié ou un ayant-droit fait une réclamation sur des données classées sensitive, alors l’éditeur en ferme temporairement l’accès (paramètre moderation, valeur off_line) et contacte le collecteur. Le collecteur décidera ensuite de la suite à donner (retrait définitif, procédure d’anonymisation, etc.).
Lorsqu’un internaute identifié ou un ayant-droit fait une réclamation sur des données classées sensitive, alors l’éditeur en ferme temporairement l’accès (paramètre moderation, valeur off_line) et contacte le collecteur. Le collecteur décidera ensuite de la suite à donner (retrait définitif, procédure d’anonymisation, etc.).
Rôles, droits et responsabilités
Rôles
Noter qu’un individu peut cumuler plusieurs des rôles qui sont distingués ci-dessous. Tous les rôles sont désignés ci-après par des noms masculins pour des raisons de commodité de lecture uniquement.![]() Collecteur (de corpus) : chercheur(s) qui a été responsable de l’expérimentation pédagogique et de la collecte des données rassemblées dans ce corpus. Le collecteur est identifié nommément : il s’agit d’un chercheur (au moins) appartenant à une institution de recherche. On notera 2 rôles OLAC (Heidi Johnson, 2006) différents.
Collecteur (de corpus) : chercheur(s) qui a été responsable de l’expérimentation pédagogique et de la collecte des données rassemblées dans ce corpus. Le collecteur est identifié nommément : il s’agit d’un chercheur (au moins) appartenant à une institution de recherche. On notera 2 rôles OLAC (Heidi Johnson, 2006) différents.![]() Éditeur (de corpus) : organisme de recherche qui a mission de structuration des corpus d’apprentissage, de réception des dépôts, de conservation des données correspondantes, de fournisseur d’accès libre sur Internet à ces données à des fins de recherche et d’enseignement. Exemple : Mulce est un éditeur de corpus, dirigé par un comité scientifique. Il dépend institutionnellement d’une université qui lui offre les conditions matérielles pour remplir ses fonctions. On peut lui donner un statut légal afin qu’il puisse héberger ses activités ailleurs, par exemple en cas de pressions administratives de la part de l’université, qui menaceraient la survie du corpus.
Éditeur (de corpus) : organisme de recherche qui a mission de structuration des corpus d’apprentissage, de réception des dépôts, de conservation des données correspondantes, de fournisseur d’accès libre sur Internet à ces données à des fins de recherche et d’enseignement. Exemple : Mulce est un éditeur de corpus, dirigé par un comité scientifique. Il dépend institutionnellement d’une université qui lui offre les conditions matérielles pour remplir ses fonctions. On peut lui donner un statut légal afin qu’il puisse héberger ses activités ailleurs, par exemple en cas de pressions administratives de la part de l’université, qui menaceraient la survie du corpus. ![]() Participant : apprenant, enseignant, voire chercheur, qui a participé à une situation d’apprentissage et qui a produit les données qui sont intégrées au corpus d’apprentissage.
Participant : apprenant, enseignant, voire chercheur, qui a participé à une situation d’apprentissage et qui a produit les données qui sont intégrées au corpus d’apprentissage.![]() (Utilisateur) internaute : internaute non identifié navigant sur le site de l’éditeur. Il peut naviguer sur une fraction significative du site de façon à en saisir la richesse et l’intérêt afin d’en parler ou de se décider à devenir contractuel pour y travailler. Certaines données lui sont masquées (via la gestion du paramètre "moderation"). De même certaines fonctionnalités lui seront inaccessibles. Exemple hors-Mulce : n’importe quel visiteur explorant librement un site partiellement ouvert comme celui de CLAPI.
(Utilisateur) internaute : internaute non identifié navigant sur le site de l’éditeur. Il peut naviguer sur une fraction significative du site de façon à en saisir la richesse et l’intérêt afin d’en parler ou de se décider à devenir contractuel pour y travailler. Certaines données lui sont masquées (via la gestion du paramètre "moderation"). De même certaines fonctionnalités lui seront inaccessibles. Exemple hors-Mulce : n’importe quel visiteur explorant librement un site partiellement ouvert comme celui de CLAPI.![]() (Utilisateur) internaute identifié. Tout internaute qui aura donné son courriel (nom et prénom), avant de pouvoir réagir dans les forums associés au site de l’éditeur. Ce peut être un participant, un chercheur ou autre personne.
(Utilisateur) internaute identifié. Tout internaute qui aura donné son courriel (nom et prénom), avant de pouvoir réagir dans les forums associés au site de l’éditeur. Ce peut être un participant, un chercheur ou autre personne. ![]() (Utilisateur) contractuel : chercheur / enseignant identifié, qui peut accéder au corpus d’apprentissage dans son intégralité. Exemple : les chercheurs/ enseignants qui se feront reconnaître sur le site Mulce et pour lesquels Mulce a été conçu.
(Utilisateur) contractuel : chercheur / enseignant identifié, qui peut accéder au corpus d’apprentissage dans son intégralité. Exemple : les chercheurs/ enseignants qui se feront reconnaître sur le site Mulce et pour lesquels Mulce a été conçu. ![]() Contributeur (de données) : tout chercheur ayant participé de façon significative au travail de constitution du corpus (exemple : collecteur, expérimentateur, transcripteur, analyste, etc.)
Contributeur (de données) : tout chercheur ayant participé de façon significative au travail de constitution du corpus (exemple : collecteur, expérimentateur, transcripteur, analyste, etc.) ![]() Responsable d’analyse : chercheur ayant réalisé des analyses à partir d’un corpus existant et désirant déposer ces nouvelles données en relation avec le corpus. Ce peut être un collecteur ou tout autre contractuel.
Responsable d’analyse : chercheur ayant réalisé des analyses à partir d’un corpus existant et désirant déposer ces nouvelles données en relation avec le corpus. Ce peut être un collecteur ou tout autre contractuel.
Droits et devoirs associés aux rôles dans Mulce
Ces droits et devoirs sont tous exercés dans le respect du code éthique décrit dans la section Accord de consentement éclairé.![]() Collecteur :
Collecteur :
— dépose les données dans Mulce selon les modalités du contrat de dépôt
— mène à bien les procédures d’anonymisation
— détient les contrats de cession des droits d’auteur des participants / sujets
— gère la question des droits d’auteur associés à tout le travail de recherche (collecte, etc.)
— signe le contrat de dépôt avec l’éditeur de corpus
— liste les noms des contributeurs associés au travail de collecte
— le cas échéant, classe comme sensible les données déposées par lui-même ou par le responsable d’analyse![]() Éditeur de corpus :
Éditeur de corpus :
— fait signer (en ligne) aux différentes parties les contrats et licences correspondantes, en particulier aux responsables de corpus et aux utilisateurs
— identifie les utilisateurs contractuels et vérifie l’appartenance de l’utilisateur à l’institution
— édite des recommandations quant aux procédures d’anonymisation, aux contenus des contrats de cession des droits
— vérifie lors du dépôt que l’anonymisation a été faite (mais n’est pas tenu de la certifier)
— assure la modération avant le passage en ligne sur les données déposées par le collecteur ou le responsable d’analyse
— en cas de réclamation, retire du site les données sensibles (et les ré-instaure par la suite si les termes de la résolution du litige le permettent)
Le site de l’éditeur sert de support de diffusion pour :
— le code de protection éthique de Mulce
— une information précisant qu’il ne détient aucune donnée sur les individus, où elles sont détenues et comment seront traitées les éventuelles demandes des intéressés, y compris un message approprié comportant l’adresse d’un contact chez l’éditeur auprès duquel s’adresser en cas de réclamation (voir exemple Encadré 1)
— une information précisant le niveau d’anonymisation des données
— le texte des contrats de cession de droits signés par les participants
Encadré 1
Modèle de message (adapté de Le Draoullec, 2006)
« Le souci de respecter les droits de chaque participant concerné par la mise en ligne des données sur ce site est un impératif qui nous a guidé dans le schéma de gestion des droits et dans les procédures d’anonymisation de ce projet.
Nous profitons de cette partie légale indispensable du site pour informer tout participant dont les données auraient échappé à l’anonymisation de notre bonne foi et de notre disponibilité pour recevoir leur plainte si des informations les concernant ont été mises en ligne sans leur autorisation. Nous les remercions par avance de leur sollicitude et de leur compréhension. Contact : xxxx »
![]() Participant signe un contrat-participant qui comprend :
Participant signe un contrat-participant qui comprend :
— le contrat de cession des droits
— le formulaire de consentement éclairé ![]() (Utilisateur) internaute
(Utilisateur) internaute
est invité (via une note affichée sur le site) à s’engager à respecter les termes de la licence Creative Commons sous laquelle sont fournies les données![]() (Utilisateur) contractuel
(Utilisateur) contractuel
— remplit un formulaire d’identification de sa personne et de son institution, signé par simple clic
— signe par simple clic son acceptation de la licence d’utilisation (la seule autre possibilité par défaut étant "n’accepte pas la licence", ce qui tend à guider l’utilisateur vers l’acceptation)![]() Contributeur de données
Contributeur de données
— peut demander à l’éditeur de voir son nom retiré des métadonnées du corpus ou des analyses![]() Responsable d’analyse
Responsable d’analyse ![]() dépose et signe un contrat de dépôt (simplifié car la partie sur les individus ne le concerne pas, contrairement à ce qui se passe pour le responsable de corpus).
dépose et signe un contrat de dépôt (simplifié car la partie sur les individus ne le concerne pas, contrairement à ce qui se passe pour le responsable de corpus).![]() liste les noms des contributeurs associés au travail d’analyse
liste les noms des contributeurs associés au travail d’analyse
Types de contrats et licences
Un contrat est un accord entre deux personnes ou deux parties. La structure contractuelle présentée ci-dessous est élaborée afin de faciliter pour toute personne exerçant un rôle dans Mulce l’exécution de ses droits et devoirs dans le respect du code éthique.![]() contrat de cession des droits et de consentement éclairé
contrat de cession des droits et de consentement éclairé
— certains contrats sont historiques (voir Formulaire de consentement)
— l’éditeur invite les chercheurs (collecteurs de corpus) à faire signer avant expérimentation un contrat de cession des droits incluant un consentement éclairé, voir Accord de consentement. ![]() contrat de dépôt
contrat de dépôt
Signé par le collecteur avec l’éditeur de corpus, il comprend les éléments suivants :
— le collecteur qui a des droits d’auteurs sur le travail de recherche accorde à l’éditeur un droit non exclusif de diffuser sans limite de temps. La diffusion est définie comme devant avoir lieu sur Internet en accès libre dans le cadre du partage des résultats de recherche (voir notion de contribution ouverte dans la déclaration de Berlin, signée par les directions de recherche internationales (Berlin, 2003).
— le collecteur s’engage à posséder tous les droits d’auteur sur les données concernées, c’est-à-dire les droits des participants et ceux des chercheurs. Il s’engage donc à communiquer les noms des chercheurs ayant participé à ce travail. Il garantit l’éditeur contre tout recours à ce sujet.
— le collecteur s’engage à posséder tous les droits de copyright sur toute donnée (image, enregistrement sonore) provenant d’un tiers fournisseur. Il garantit l’éditeur contre tout recours à ce sujet.
— le collecteur s’engage à communiquer le formulaire de contrat de cession des droits d’utilisateur qu’il a fait signer aux participants
— le collecteur s’engage à anonymiser les données et à identifier les données qui pourraient être sensibles (en ayant obtenu l’accord des personnes sur ce degré de non anonymisation)
— le responsable s’engage à répondre à toute demande de l’éditeur suite à des réclamations venant de participants![]() code de protection éthique : il figure uniquement sur le site de l’éditeur. Il indique que l’ensemble du travail a été accompli dans un esprit de protection de la vie privée. Mulce a choisi de s’inscrire dans le courant européen du code de conduite éthique de la recherche en sciences sociales, inspiré des positions assez avancées du JISC
code de protection éthique : il figure uniquement sur le site de l’éditeur. Il indique que l’ensemble du travail a été accompli dans un esprit de protection de la vie privée. Mulce a choisi de s’inscrire dans le courant européen du code de conduite éthique de la recherche en sciences sociales, inspiré des positions assez avancées du JISC![]() licence Creative Commons : elle permet à un individu d’exercer ses droits d’auteur tout en autorisant certaines utilisations de ses travaux ; elle est signée par tous les utilisateurs et notifiée aux contributeurs, responsables de corpus et d’analyse. La licence qui intéresse en particulier Mulce oblige à la reconnaissance de paternité lors de l’utilisation de l’œuvre, autorise la diffusion, l’utilisation à des fins non commerciales et autorise les œuvres dérivées mais qui seront ensuite diffusées sous le même contrat de licence. Pour des fins commerciales, l’autorisation doit être demandée au cas par cas.
licence Creative Commons : elle permet à un individu d’exercer ses droits d’auteur tout en autorisant certaines utilisations de ses travaux ; elle est signée par tous les utilisateurs et notifiée aux contributeurs, responsables de corpus et d’analyse. La licence qui intéresse en particulier Mulce oblige à la reconnaissance de paternité lors de l’utilisation de l’œuvre, autorise la diffusion, l’utilisation à des fins non commerciales et autorise les œuvres dérivées mais qui seront ensuite diffusées sous le même contrat de licence. Pour des fins commerciales, l’autorisation doit être demandée au cas par cas.![]() formulaire d’identification : rempli par l’utilisateur contractuel : l’identifie lui et son institution
formulaire d’identification : rempli par l’utilisateur contractuel : l’identifie lui et son institution![]() licence d’utilisation : signée par le contractuel auprès de l’éditeur. Elle rappelle les obligations du contractuel à utiliser ces corpus dans les mêmes conditions que l’éditeur (notamment dans les pays non-européens) : respect du code éthique, transitivité des termes de la licence Creative Commons, engagement de réponse aux demandes des individus qui estimeraient avoir été lésés (voir Que faire en cas de réclamation ?")
licence d’utilisation : signée par le contractuel auprès de l’éditeur. Elle rappelle les obligations du contractuel à utiliser ces corpus dans les mêmes conditions que l’éditeur (notamment dans les pays non-européens) : respect du code éthique, transitivité des termes de la licence Creative Commons, engagement de réponse aux demandes des individus qui estimeraient avoir été lésés (voir Que faire en cas de réclamation ?")![]() contrat de dépôt simplifié : signé par le responsable d’analyse, il est identique au contrat de dépôt sus-mentionné, mais ne contient pas les éléments concernant les participants.
contrat de dépôt simplifié : signé par le responsable d’analyse, il est identique au contrat de dépôt sus-mentionné, mais ne contient pas les éléments concernant les participants.
Tableau récapitulatif des droits et devoirs dans Mulce
Protocoles éthique et droits
La diffusion de documents écrits portant trace de l’identité des personnes, ou encore de documents audio-visuels comportant des enregistrements de voix des personnes et de leurs images (exemple les corpus recueillis sur des plateformes audio-ou video- graphiques synchrones), implique une double démarche de respect des droits dont certains individus ou collectifs sont propriétaires, et de protection des données personnelles imputables à l’individu. Le partage de ces documents à l’international entraîne l’adoption de protocoles qui soient à la fois praticables dans les pays où existent encore certains vides juridiques à ce sujet, et compatibles avec ceux en vigueur dans les pays qui s’en sont déjà dotés.
On distinguera deux types de droits :
![]() le droit de traiter, transformer, disséminer et protéger les données de la recherche dont on est l’auteur ou sur lesquelles on travaille (ceci s’applique surtout aux chercheurs, mais aussi aux apprenants et tuteurs) ;
le droit de traiter, transformer, disséminer et protéger les données de la recherche dont on est l’auteur ou sur lesquelles on travaille (ceci s’applique surtout aux chercheurs, mais aussi aux apprenants et tuteurs) ;
![]() le droit de voir les données que l’on a fournies en tant que sujet de la recherche protégées (ceci s’applique uniquement aux apprenants et aux tuteurs).
le droit de voir les données que l’on a fournies en tant que sujet de la recherche protégées (ceci s’applique uniquement aux apprenants et aux tuteurs).
Terminologie
Noter l’utilisation de l’anglais pour nommer les paramètres : exemples anonymous, contractual, sensitive.
Anonymer ou anonymiser :
En anglais un ‘anonymizer’ (USA) ou un ‘anonymiser’ (Brit) est un programme qui rend anonyme. Dans le dictionnaire de l’OLF au Canada, on dit "anonymiser" (http://w3.granddictionnaire.com/BTML), avec le correspondant "anonymize/ise" en anglais. Nous faisons ici la proposition, afin de fixer l’usage au sein de Mulce, d’adopter la version avec le suffixe –ise, qui fonctionne aussi en français même si elle se double d’une version sans le suffixe (ex : anonymer). Nous proposons donc : anonymiser, anomymisé, anomymisation.
Open Access
Pour gérer les données dites sensibles, le système Mulce dispose d’un paramètre "moderation" associé aux données / structures (à un certain niveau de granularité qui sera défini dans l’autre rapport) qui a deux valeurs : "on_line", "off_line". Malgré le rapprochement instinctif que l’on peut faire entre la notion de ‘donner accès’ et de ‘refuser l’accès’ à des données sensibles, nous éviterons la dénomination ‘access’ pour ce paramètre, du fait de la connotation de ce terme par rapport à l’ « open access ».
![]() Baude, O., Blanche-Benveniste, B., Calas M.F., Cordereix, P., De Lamberterie, I., Gourie, L., Jacobson, M., Marchello-Nizia, C. & Mondada, L. (dir.) (2005). Guide des bonnes pratiques pour la constitution, exploitation, conservation et diffusion des corpus oraux. Paris : Editions du CNRS et DGLF-LF http://www.culture.gouv.fr/culture/...
Baude, O., Blanche-Benveniste, B., Calas M.F., Cordereix, P., De Lamberterie, I., Gourie, L., Jacobson, M., Marchello-Nizia, C. & Mondada, L. (dir.) (2005). Guide des bonnes pratiques pour la constitution, exploitation, conservation et diffusion des corpus oraux. Paris : Editions du CNRS et DGLF-LF http://www.culture.gouv.fr/culture/...![]() Berlin (2003). Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities. October. http://oa.mpg.de/openaccess-berlin/...
Berlin (2003). Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities. October. http://oa.mpg.de/openaccess-berlin/...![]() Billig, M. (1999) Whose Terms ? Whose Ordinariness ? Rhetoric and Ideology in Conversation Analysis. Discourse & Society, Vol. 10 (4) 543-582.
Billig, M. (1999) Whose Terms ? Whose Ordinariness ? Rhetoric and Ideology in Conversation Analysis. Discourse & Society, Vol. 10 (4) 543-582. ![]() CNIL (2007). Site de la Commission Information et Liberté. CNIL : Paris. http://www.cnil.fr
CNIL (2007). Site de la Commission Information et Liberté. CNIL : Paris. http://www.cnil.fr![]() CORINTE (2007). Site dde documentation de CLAPI (CORpus d’INTEractions) http://icar.univ-lyon2.fr/projets/c...
CORINTE (2007). Site dde documentation de CLAPI (CORpus d’INTEractions) http://icar.univ-lyon2.fr/projets/c...![]() Creative Commons France (2010) http://fr.creativecommons.org/
Creative Commons France (2010) http://fr.creativecommons.org/![]() Daigremont, P. (2007) Traduction "Les différents droits" de la licence Creative Commons. http://philippe.daigremont.free.fr/...
Daigremont, P. (2007) Traduction "Les différents droits" de la licence Creative Commons. http://philippe.daigremont.free.fr/...![]() JISC (2007) Joint Information Systems Committee Data protection Code of Practice for the Higher Education and Further Education Sectors, Version 2.0 http://www.jisc.ac.uk/uploaded_docu...
JISC (2007) Joint Information Systems Committee Data protection Code of Practice for the Higher Education and Further Education Sectors, Version 2.0 http://www.jisc.ac.uk/uploaded_docu...![]() Draoullec, Ludovic Le. (2006) L’utilisation des corpus oraux à des fins culturelles : quels contrats mettre en œuvre ? AFAS - Association française des détenteurs de documents sonores et audiovisuels,
Draoullec, Ludovic Le. (2006) L’utilisation des corpus oraux à des fins culturelles : quels contrats mettre en œuvre ? AFAS - Association française des détenteurs de documents sonores et audiovisuels,
http://afas.imageson.org/document62...![]() Oates, J. (2006) Ethical frameworks for research with human participants. In Stephen Potter (dir) Doing Postgraduate Research. London : Sage. pp 200-228.
Oates, J. (2006) Ethical frameworks for research with human participants. In Stephen Potter (dir) Doing Postgraduate Research. London : Sage. pp 200-228.