
Nous décrivons dans cet article les principes généraux ayant conduit à la structuration des objets déposés dans la banque de corpus ou plate-forme Mulce ( http://repository.mulce.org). D’autres articles de cette rubriques détaillent chaque composant. Le lecteur désireux d’avoir des exemples d’objets déposés et de savoir comment se servir de cette plate-forme se reportera aux articles de la rubrique Démo-utilisation
XML pour décrire nos objets
L’équipe Mulce a choisi de décrire les corpus d’apprentissage avec le langage XML pour plusieurs raisons :
![]() Les données des corpus nécessites d’être structurées, mais pas de manière aussi rigide et immuable que dans les bases de données conventionnelles. Ainsi, XML offre la possibilité de structurer les données, de les adapter et de rendre la structuration et l’adaptation explicites.
Les données des corpus nécessites d’être structurées, mais pas de manière aussi rigide et immuable que dans les bases de données conventionnelles. Ainsi, XML offre la possibilité de structurer les données, de les adapter et de rendre la structuration et l’adaptation explicites.
![]() Les corpus doivent pouvoir être copiés et retravaillés dans des contextes éventuellement différents. Quand on copie un fichier XML, on copie aussi toutes les références aux schémas qui rendent sa structuration explicite.
Les corpus doivent pouvoir être copiés et retravaillés dans des contextes éventuellement différents. Quand on copie un fichier XML, on copie aussi toutes les références aux schémas qui rendent sa structuration explicite.
![]() Des portions de corpus : typiquement des fragments de séances ou de listes d’interactions peuvent être extraits. En XML, les balises encadrent chacun des éléments et des étiquettes précisent chacun des attributs de ces éléments. Ainsi, les noms des éléments et des attributs sont nécessairement dans les fragments de données copiées. Ce n’est pas du tout le cas quand on copie une sélection de lignes d’un tableau : parfois, les en-têtes de colonnes sont perdus.
Des portions de corpus : typiquement des fragments de séances ou de listes d’interactions peuvent être extraits. En XML, les balises encadrent chacun des éléments et des étiquettes précisent chacun des attributs de ces éléments. Ainsi, les noms des éléments et des attributs sont nécessairement dans les fragments de données copiées. Ce n’est pas du tout le cas quand on copie une sélection de lignes d’un tableau : parfois, les en-têtes de colonnes sont perdus.
![]() Enfin, XML est un langage suffisamment répandu dans le monde de la recherche aujourd’hui pour permettre d’une part aux concepteurs de réutiliser des descripteurs et schémas normalisés existant pour construire nos propres structures, et d’autre part aux chercheurs de mieux réutiliser des corpus dont la structure des données est explicite.
Enfin, XML est un langage suffisamment répandu dans le monde de la recherche aujourd’hui pour permettre d’une part aux concepteurs de réutiliser des descripteurs et schémas normalisés existant pour construire nos propres structures, et d’autre part aux chercheurs de mieux réutiliser des corpus dont la structure des données est explicite.
Empaquetage des objets Mulce : IMS-CP
Parmi les schémas standard existants dans le monde des technologies de l’apprentissage en ligne, nous avons rapidement (certains diraient trop rapidement) adopté IMS-CP pour l’empaquetage de nos objets et IMS-LD pour décrire nos propres scénarios pédagogiques. Ces schémas sont des productions du consortium IMS (Instruction Management System).
Le principe de base de IMS-CP (Content Package) est d’encapsuler dans une archive, un ensemble de fichiers (hétérogènes) placés dans un dossier de contenus, et d’accompagner cet ensemble d’un manifeste.
Ce manifeste, écrit en XML, peut décrire des métadonnées (metadata), des données et les liens entre ces informations (organizations), et les fichier de l’archive (resources). La structuration d’un manifeste est donnée par le schéma (IMS-CP, 2007) dont une présentation simplifiée des principaux élément est faite dans la figure ci-dessous.
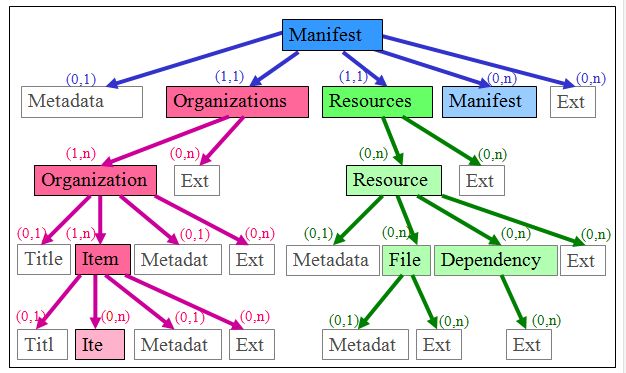
Comme on peut le remarquer sur cette figure, le schéma de IMS-CP autorise l’élément racine à contenir récursivement un (sous-)élément . Mais les corpus Mulce n’utilisent pas cette possibilité car tout élément dans un sous-arbre de doit pouvoir faire référence à toute ressource déclarée dans l’archive. Or, un sous- doit être indépendant (détachable) de toute autre partie.
Au premier niveau, Mulce utilise donc les trois premiers éléments :
![]() l’élément du premier niveau pour y placer de multiples descriptions ;
l’élément du premier niveau pour y placer de multiples descriptions ;![]() l’élément pour y placer chacun des composants (organization ou Ext),
l’élément pour y placer chacun des composants (organization ou Ext),![]() l’élément fils (au format IMS-CP) n’est utilisé que par les composants très simples tels que la Licence ou un composant faisant seulement référence à des documents de l’archive (html, documents textes,…) ;
l’élément fils (au format IMS-CP) n’est utilisé que par les composants très simples tels que la Licence ou un composant faisant seulement référence à des documents de l’archive (html, documents textes,…) ;![]() Mais pour les composants complexes, on redéfinit en général cet élément (il est donc interprété comme un élément extérieur Ext.). C’est le cas en particulier pour les composants au format IMS-LD ou pour les traces d’interactions (SID).
Mais pour les composants complexes, on redéfinit en général cet élément (il est donc interprété comme un élément extérieur Ext.). C’est le cas en particulier pour les composants au format IMS-LD ou pour les traces d’interactions (SID).![]() l’élément pour y déclarer tous les fichiers de l’archive.
l’élément pour y déclarer tous les fichiers de l’archive.
IMS-LD est utilisé pour décrire de façon précise le scénario pédagogique de la formation ou le protocole de recherche . Cette structuration est facultative. Une simple description textuelle peut suffire. On trouvera :
- un exemple de protocole de recherche dans ce corpus oai:mulce.org:mce-copeas-rp-all
- un exemple de scénario pédagogique dans ce corpus : oai:mulce.org:mce-simu-ld-01
Pour les interactions, compte tenu de leur diversité (courriels, blogues, forums, clavardage, communication audio, par icône, déplacements d’avatars, etc.), nous avons dû développer une structure XML spécifique permettant de décrire chaque type d’acte / interaction. Cette partie interaction (SID - Structure Interaction Data) est couplé avec une description XML des environnements d’apprentissage et des acteurs. L’ensemble se dénomme "Mulce-struct". Pour en savoir plus :
- article présentant Mulce-strcut et le SID : Reffay, Chanier, Noras, & Betbeder, 2008)
- schéma du SID : Mce_sid_letec, 2011
Des métadonnées pour caractériser nos objets
Les métadonnées sont par essence des données (ou informations) sur les données. Elles servent le plus souvent à caractériser un objet (ici un corpus par exemple) par des informations homogènes, relativement à une collection d’objets. Pour formuler définir correctement les métadonnées, il faut donc bien connaître à la fois l’objet à décrire (côté auteur/créateur) et les caractéristiques de la collection dans laquelle il doit être déposé (côté éditeur).
Dans le cas de Mulce, les métadonnées fournies dans nos objets répondent à quatre points de vue qui concernent ces objets directement :
![]() Les informations du Dublin Core qui regardent la ressource comme une entitée documentaire.
Les informations du Dublin Core qui regardent la ressource comme une entitée documentaire.![]() L’archive OLAC (i.e. : Open Language Archive Community) qui considère nos corpus comme des données d’interaction langagières,
L’archive OLAC (i.e. : Open Language Archive Community) qui considère nos corpus comme des données d’interaction langagières,![]() Les informations de la LOM (Learning Object Metadata) qui s’intéressent uniquement à l’aspect pédagogique de la ressource,
Les informations de la LOM (Learning Object Metadata) qui s’intéressent uniquement à l’aspect pédagogique de la ressource, ![]() L’archive Mulce (Multimodal Learning and teaching Corpora Exchange) qui considère ces objets comme des ressources partagées pour la recherche dans le domaine de l’apprentissage en ligne.
L’archive Mulce (Multimodal Learning and teaching Corpora Exchange) qui considère ces objets comme des ressources partagées pour la recherche dans le domaine de l’apprentissage en ligne.
Pour les 3 premiers points, nous avons essentiellement réutilisé des schémas écrits par d’autres, et pour le quatrième, nous avons produit nos propres schémas (un pour les corpus globaux, un autre pour les corpus distinguables, voir les références ci-dessous) .
IMS-CP, 2007 : Schema for IMS Content Package. Copyright © IMS Global Learning Consortium 1999-2007. Root element . http://www.imsglobal.org/xsd/imscp_...
Mce-letec-disting, 2009 : Structuration spécifique de l’élément pour les corpus distinguables. Root element : < organization>. http://lrl-diffusion.univ-bpclermon...
Mce_letec_meta, 2009 : Structuration des metadonnées d’un corpus d’apprentissage (LETEC). Root element : . http://lrl-diffusion.univ-bpclermon...
Mce_olac_letec, 2009 : Extension a OLAC des types (letec) et rôles (contributor) pour qualifier les métadonnées des objets Mulce. http://mulce.univ-fcomte.fr/metadat...
Mce_sid_letec, 2011 : schéma décrivant les différentes structures d’interactions http://lrl-diffusion.univ-bpclermon...
Reffay, C., Chanier, T., Noras, M., Betbeder, M.-L. (2008) Contribution à la structuration de corpus d’apprentissage pour un meilleur partage en recherche, Sciences et Technologies de l’Information et de la Communication pour l’Education et la Formation, STICEF, 15 (2008) http://edutice.archives-ouvertes.fr...