
Un corpus d’apprentissage (LETEC) assemble de façon systématique et structurée un ensemble de données, particulièrement d’interactions, et de traces issues d’une expérimentation de formation partiellement ou totalement en ligne, enrichies par des informations techniques, humaines, pédagogiques et scientifiques permettant leur analyse en contexte

vue d’ensemble constituants d’un corpus d’apprentissage
Corpus d’apprentissage, définition
Un corpus d’apprentissage, LETEC, (Learning & Teaching Corpus) est constitué autour de l’objet d’étude résultant d’une situation de formation / apprentissage en ligne. Le corpus primaire rassemble l’ensemble des données d’interaction, de production des acteurs engagés dans la formation, complété par les traces des actions laissées par ces acteurs dans le système. On y trouve donc des éléments comme les courriels, forums, clavardages, interactions issues d’environnements audio-vidéo graphiques synchrones, vidéo d’écran, données audio, traces (logs) système etc.
Le cadre (ou contexte) qui permet au chercheur à la fois de donner du sens à ces données (offrir un cadre interprétatif) et d’ouvrir la porte aux analyses est constitué principalement par :
![]() le cadre pédagogique : scénario pédagogique (incluant pré-requis, objectifs pédagogiques, contenus et tâches), données sur les acteurs ;
le cadre pédagogique : scénario pédagogique (incluant pré-requis, objectifs pédagogiques, contenus et tâches), données sur les acteurs ;![]() le cadre de recherche (s’il existe), qui peut lui aussi apporter son lot de données primaires sur les acteurs (questionnaires, entretiens, etc.), ainsi qu’un scénario (ou protocole) de recherche, qui a mis à contribution les acteurs de la formation dans des activités spécifiques, planifiées en pré-, post-formation ou au cours de son déroulement.
le cadre de recherche (s’il existe), qui peut lui aussi apporter son lot de données primaires sur les acteurs (questionnaires, entretiens, etc.), ainsi qu’un scénario (ou protocole) de recherche, qui a mis à contribution les acteurs de la formation dans des activités spécifiques, planifiées en pré-, post-formation ou au cours de son déroulement.
Le tout (données et contexte) est organisé en vue de l’analyse de ces situations d’apprentissage en ligne. Données et analyses devant pouvoir circuler librement au sein des communautés de recherche, la partie "Licences" d’un corpus d’apprentissage se rapporte aux questions de droits et éthique.
Constituants du corpus
La figure ci-avant schématise les différentes parties du corpus.
![]() Le dispositif pédagogique peut-être librement décrit, mais il est préférable de le faire de façon détaillée en précisant le scénario pédagogique, les différents rôles des participants, en particulier des apprenants et enseignants, ainsi que les environnements technologiques retenus avec leurs fonctionnalités, et leurs caractéristiques dédiées aux interactions.
Le dispositif pédagogique peut-être librement décrit, mais il est préférable de le faire de façon détaillée en précisant le scénario pédagogique, les différents rôles des participants, en particulier des apprenants et enseignants, ainsi que les environnements technologiques retenus avec leurs fonctionnalités, et leurs caractéristiques dédiées aux interactions.
![]() De la même façon, si l’expérimentation inclue un protocole de recherche, le rôle des chercheurs, le séquencement des activités afférentes (administration de questionnaires, entretiens, etc.) seront utilement décrits.
De la même façon, si l’expérimentation inclue un protocole de recherche, le rôle des chercheurs, le séquencement des activités afférentes (administration de questionnaires, entretiens, etc.) seront utilement décrits.
![]() Les deux parties précédentes correspondent à ce qui était prévu avant le déroulement de la formation, à un modèle donc. Suivant la terminologie des langages objets, le modèle s’instancie lors de l’acte pédagogique (avec tous les changements inopinés afférents). La partie instanciation assemble donc, d’une part, les enregistrements des interactions des participants (sous formes textuelle, audio ou vidéo), leur productions individuelles (tels que les travaux écrits ou oraux, les journaux de bord) et, le cas échéant, les traces système (temps de connexion, statistiques de participation, etc.). Elle regroupe d’autre part, le cas échéant, les questionnaires remplis, les enregistrements d’entretiens, les matériaux afférents (grille d’entretien, matériaux pour auto-confrontation, etc.).
Les deux parties précédentes correspondent à ce qui était prévu avant le déroulement de la formation, à un modèle donc. Suivant la terminologie des langages objets, le modèle s’instancie lors de l’acte pédagogique (avec tous les changements inopinés afférents). La partie instanciation assemble donc, d’une part, les enregistrements des interactions des participants (sous formes textuelle, audio ou vidéo), leur productions individuelles (tels que les travaux écrits ou oraux, les journaux de bord) et, le cas échéant, les traces système (temps de connexion, statistiques de participation, etc.). Elle regroupe d’autre part, le cas échéant, les questionnaires remplis, les enregistrements d’entretiens, les matériaux afférents (grille d’entretien, matériaux pour auto-confrontation, etc.).
![]() La partie publique de la licence donne accès aux licences d’utilisation du corpus par la communauté de chercheurs et praticiens (Mulce a choisi une licence Creative Commons) et les formulaires de contrat d’éthique remis aux participants. La partie privée de la licence, n’est pas directement intégrée au corpus, mais conservée par le responsable du corpus. Elle incorpore notamment les patronymes et coordonnées des participants, ainsi que les contrats signés.
La partie publique de la licence donne accès aux licences d’utilisation du corpus par la communauté de chercheurs et praticiens (Mulce a choisi une licence Creative Commons) et les formulaires de contrat d’éthique remis aux participants. La partie privée de la licence, n’est pas directement intégrée au corpus, mais conservée par le responsable du corpus. Elle incorpore notamment les patronymes et coordonnées des participants, ainsi que les contrats signés.
![]() Les analyses ne font pas en général pas partie du corpus d’apprentissage, mais seront adjointes ultérieurement sous forme de corpus distinguables (voir ci-après). Quant au cas intermédiaire des transcriptions des enregistrements vidéo ou audio, nous les avons intégrées dans les corpus déposés dans le serveur Mulce , en sachant qu’elles peuvent être recommencées ou modifiées. Le schéma de la figure fait apparaître la partie analyse comme l’objectif orientant l’ensemble de l’effort de collecte et d’organisation.
Les analyses ne font pas en général pas partie du corpus d’apprentissage, mais seront adjointes ultérieurement sous forme de corpus distinguables (voir ci-après). Quant au cas intermédiaire des transcriptions des enregistrements vidéo ou audio, nous les avons intégrées dans les corpus déposés dans le serveur Mulce , en sachant qu’elles peuvent être recommencées ou modifiées. Le schéma de la figure fait apparaître la partie analyse comme l’objectif orientant l’ensemble de l’effort de collecte et d’organisation.
Des corpus de granularité différentes
Un corpus d’apprentissage correspondant à une expérience de formation est un méga corpus comportant une trop grande quantité de données pour pouvoir offrir des objets aisément analysables. Il devient alors nécessaire de travailler à partir d’unité intermédiaire, d’où la constitution de corpus distinguables. Ces différents types de corpus présents dans notre base de corpus en ligne (url à modifier) sont détaillés dans l’article Corpus distinguable, corpus global du site.
Structure d’un corpus
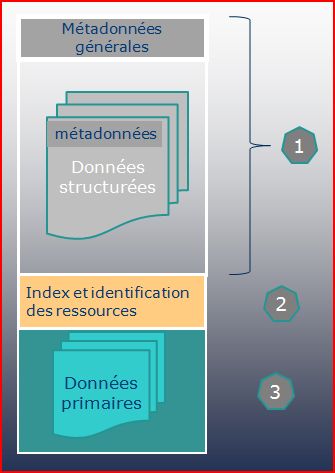
La partie ci-avant indique comment toutes les données et informations du LETEC s’organisent.
![]() En 3, figurent les données primaires des différentes parties (consignes pédagogiques, traces des interactions, questionnaires et entretiens, etc.), dans les formats nécessaires à leur conservation et utilisation. Le qualificatif "primaire" adjoint à ces données, suivant la terminologie courante des corpus en linguistique, est quelque peu abusif, puisqu’une partie des formats des documents, (textes, vidéogrammes, audiogrammes) pourront être transformés et les documents eux-mêmes anonymisés, plus ou moins profondément, suivant les exigences précitées.
En 3, figurent les données primaires des différentes parties (consignes pédagogiques, traces des interactions, questionnaires et entretiens, etc.), dans les formats nécessaires à leur conservation et utilisation. Le qualificatif "primaire" adjoint à ces données, suivant la terminologie courante des corpus en linguistique, est quelque peu abusif, puisqu’une partie des formats des documents, (textes, vidéogrammes, audiogrammes) pourront être transformés et les documents eux-mêmes anonymisés, plus ou moins profondément, suivant les exigences précitées.
![]() En 2, sont regroupées les index, identifiants et informations résumées sur chacune des ressources de la partie 3. Cette partie est structurée, laissant ainsi apparaître les groupes de ressources correspondant, par exemple, à un ensemble de consignes pédagogiques, un ensemble de données pour des entretiens semi-directifs, ou un ensemble de fichiers permettant d’aligner transcriptions et vidéo (cf. exemple plus loin).
En 2, sont regroupées les index, identifiants et informations résumées sur chacune des ressources de la partie 3. Cette partie est structurée, laissant ainsi apparaître les groupes de ressources correspondant, par exemple, à un ensemble de consignes pédagogiques, un ensemble de données pour des entretiens semi-directifs, ou un ensemble de fichiers permettant d’aligner transcriptions et vidéo (cf. exemple plus loin).
![]() La partie 1 est entièrement structurée, avec le langage de balisage XML, suivant un ensemble de schémas. Elle contient un premier ensemble de métadonnées générales du corpus, au format OLAC, qui lui permette d’être identifié, depuis le serveur Mulce, par les internautes et les serveurs moissonneurs de la Toile, suivant les protocoles déjà mentionnés. Figurent ensuite, pour chaque partie du corpus, les informations structurées afférentes. Pour ce qui concerne les interactions, nous avons mis au point une structure, correspondant au schéma Mulce-struct (Reffay et al., 2008 : s.3.3.2), dans laquelle sont encodés de façon homogène les messages de courriels, de forums, de blogues les modalités des environnements audio-graphiques (audio, clavardage, iconique, actes de production dans des tableaux blancs, traitement de texte partagé, carte conceptuelle, blogue, etc.). Le contenu des actes, résultats de transcription (Chanier et Vetter, 2006) ou des traces système, est en correspondance avec les environnements technologiques et les participants. Une autre partie de la structure code, justement les informations ethnographiques et éléments de bibliographie langagière, essentiels pour les analyses linguistiques ultérieures (Belz et Vyatkina, 2008 : 45). De même, si les collecteurs et éditeurs du corpus ont choisi de structurer les informations concernant le dispositif pédagogique, alors chaque acte attaché à une interaction peut-être automatiquement mis en rapport avec le contexte pédagogique (activité, rôle des participants, consignes, etc.). Pour les premiers corpus d’apprentissage déposés dans le serveur Mulce, nous avons choisi d’utiliser les modèles standard développés par la communauté IMS Global Learning Consortium(IMS, 2009) modèles par ailleurs souvent utilisés dans les cursus de formation d’ingénieur pédagogique dans les phases de conception de situations d’apprentissage.
La partie 1 est entièrement structurée, avec le langage de balisage XML, suivant un ensemble de schémas. Elle contient un premier ensemble de métadonnées générales du corpus, au format OLAC, qui lui permette d’être identifié, depuis le serveur Mulce, par les internautes et les serveurs moissonneurs de la Toile, suivant les protocoles déjà mentionnés. Figurent ensuite, pour chaque partie du corpus, les informations structurées afférentes. Pour ce qui concerne les interactions, nous avons mis au point une structure, correspondant au schéma Mulce-struct (Reffay et al., 2008 : s.3.3.2), dans laquelle sont encodés de façon homogène les messages de courriels, de forums, de blogues les modalités des environnements audio-graphiques (audio, clavardage, iconique, actes de production dans des tableaux blancs, traitement de texte partagé, carte conceptuelle, blogue, etc.). Le contenu des actes, résultats de transcription (Chanier et Vetter, 2006) ou des traces système, est en correspondance avec les environnements technologiques et les participants. Une autre partie de la structure code, justement les informations ethnographiques et éléments de bibliographie langagière, essentiels pour les analyses linguistiques ultérieures (Belz et Vyatkina, 2008 : 45). De même, si les collecteurs et éditeurs du corpus ont choisi de structurer les informations concernant le dispositif pédagogique, alors chaque acte attaché à une interaction peut-être automatiquement mis en rapport avec le contexte pédagogique (activité, rôle des participants, consignes, etc.). Pour les premiers corpus d’apprentissage déposés dans le serveur Mulce, nous avons choisi d’utiliser les modèles standard développés par la communauté IMS Global Learning Consortium(IMS, 2009) modèles par ailleurs souvent utilisés dans les cursus de formation d’ingénieur pédagogique dans les phases de conception de situations d’apprentissage.
Signalons que ces trois parties sont enveloppées dans un container (content packaging) correspondant à l’un des format prescrit par IMS, la partie 1 étant dénommée le manifeste. C’est ce même format qui est souvent utilisé pour échanger des ressources pédagogiques entre plates-formes de téléformation.
Pour une description plus détaillée de cette structuration voir l’article Structure des objets de l’archive Mulce de notre site.
![]() Reffay, C., Chanier, T., Noras, M. & Betbeder, M.-L. (2008). "Contribution à la structuration de corpus d’apprentissage pour un meilleur partage en recherche". In Basque, J. & Reffay, C. (dir.), numéro spécial EPAL (échanger pour apprendre en ligne), Sciences et Technologies de l’Information et de la Communication pour l’Education et la Formation (Sticef), vol. 15, http://sticef.univ-lemans.fr/num/vo...
Reffay, C., Chanier, T., Noras, M. & Betbeder, M.-L. (2008). "Contribution à la structuration de corpus d’apprentissage pour un meilleur partage en recherche". In Basque, J. & Reffay, C. (dir.), numéro spécial EPAL (échanger pour apprendre en ligne), Sciences et Technologies de l’Information et de la Communication pour l’Education et la Formation (Sticef), vol. 15, http://sticef.univ-lemans.fr/num/vo...![]() Chanier, T. & Ciekanski, M. (2010, à paraître) "Utilité du partage des corpus pour l’analyse des interactions en ligne en situation d’apprentissage : un exemple d’approche méthodologique autour d’une base de corpus d’apprentissage". Apprentissage des Langues et Systèmes d’Information et de Communication (ALSIC) http://edutice.archives-ouvertes.fr...
Chanier, T. & Ciekanski, M. (2010, à paraître) "Utilité du partage des corpus pour l’analyse des interactions en ligne en situation d’apprentissage : un exemple d’approche méthodologique autour d’une base de corpus d’apprentissage". Apprentissage des Langues et Systèmes d’Information et de Communication (ALSIC) http://edutice.archives-ouvertes.fr...![]() Reffay, C. and Betbeder, M.-L. (2009) . Sharing corpora and tools to improve interaction analysis. In EC-TEL 2009, 4th European Conference on Technology Enhanced Learning, Nice, France, October 2009 http://edutice.archives-ouvertes.fr...
Reffay, C. and Betbeder, M.-L. (2009) . Sharing corpora and tools to improve interaction analysis. In EC-TEL 2009, 4th European Conference on Technology Enhanced Learning, Nice, France, October 2009 http://edutice.archives-ouvertes.fr...